
Access, download and process Results from NECTA in R
The the National Examinations Council of Tanzania publishes Primary and Secondary Education Examination Results. But the National Library Services archieve this results. While a fantastic resource for history primary and secondary school results, these records are painful to analyze using software because of the grades results is organized is untidy and in messy.
You need to work on this column of the result to have a clean and right format dataset for exploration and modelling. The tidyverse ecocystem has two excellent packages for manipulating files that are not amenable to analysis because of inconsistencies and structure: tidyr provides many tools for cleaning up messy data, dplyr provides many tools for restructuring data.
The tables are in HTML tables—a standard way to display tabular information online. But tables on the web are primarily designed for displaying and consuming data, not for analytical purposes. To make working with HTML tables easier and less time-consuming, Christian Rubba (2016) developed a htmltab package for the R system that tries to alleviate these problems directly in the parsing stage when the structural information is still available.
Load Packages
This post uses R packages, which are collections of R code that help users code more efficiently. We load these packages with the function require(). The specific packages we’ll use here include tidyverse for data manipulation and visualization (Wickham and Wickham 2017) and htmltab to import HTML tables into data frame (Rubba 2016) and readxl for export of the structured dataset into Excel (Wickham and Bryan 2018). If you have not installed any of these packages before, you will need to do so before loading them (if you run the code below prior to installing the packages, you should see a message indicating that the package is not available). If you have installed these before, then you can skip this step.
You can install these package, as follows:
packs = c("tidyverse", "htmltab)
install.packages(packs)Once you have installed the package, you can simply them into your session using a require() function. Please note that you only need to install the package once, and when is already installed, the next time you want to use it you simply load it into the session.
require(tidyverse)
require(htmltab)The 2019 Secondary Education Results
I will use a 2019 Form IV results to demostrate the idea. The results are hosted at this link. Is a HTML table and we can only read this using the right function in R. For this post I will use the htmltab function from htmltab package (Rubba 2016). At a minimum, htmltab() needs to be fed the HTML document as well as an information where to find the table in the page. After a bit of testing out , I found that it is the 3rd table in the page, so I pass 9 to the which argument:
index = htmltab::htmltab(doc = "https://maktaba.tetea.org/exam-results/CSEE2019/csee.htm", which = 3)We can print the dataset to have a glimpse of the ten rows. We notice that the file structure is similar to the table format in the html document. It contains three columns. But the function used the first row observation as the column names. We need to structure the data and ensure Ilboru is one of the observation of the dataset and not the variable name. We give the data its contents
index %>%
# head() %>%
as_tibble()Create School Index
We need to create a data frame that has three columns for school index, school name and the year of exam results. With that dataset will be able to pull results of each school. First we need to change the variable name in the index dataset into rows, there is no straight function to do that particular task, I created a simple function to that for me. This function will return the data frame with columns as observation, which is actually what is suppose to be.
var2row = function(x){
require(tidyverse)
data = x %>%
names() %>%
t() %>%
as_tibble() %>%
rename(column1 = 1, column2 = 2, column3 = 3)
return(data)
}Once we have created the function, we can use to create the firs row of observation in the dataset from the index dataset. We simply return the observation in its place
firs.row = index %>%
var2row()
firs.rowWe can now stitch the first row data we simply created above with the observation in the index dataset. We do that using abind_rows function from dplyr package (Wickham et al. 2019). We need to change the column names for the index dataset to match those in the firs.row dataset before we bind them.
## rename
index = index %>%
rename(column1 = 1, column2 = 2, column3 = 3)
## stitch them together
index = firs.row %>%
bind_rows(index)The index structure is in the format widely known as wide format, but we need to transform it to long format. I use a pivot_longer function from dplyr package to transform the dataset (Wickham et al. 2019).
`
index = index %>%
pivot_longer(cols = 1:3, names_to = "column", values_to = "school")
indexThe pivot_longer function changes the shape of the dataset from three columns to two. It moves the variable names to a new columnand all school to a new school column, which contains the index and name of each school as observations.
We also need to separate the index and school name into separate columns. We can do that using the separate function from tidyr package (Wickham and Henry 2018). Careful looking on the index is the mixture of letter and number forming a five number characters. We can use this as a criterion to separate the school into index and name and add a new column using a mutate function form dplyr package (Wickham et al. 2019)
schools.index = index %>%
select(-column) %>%
separate(col = school, into = c("index", "name"), sep = 5) %>%
mutate(index = tolower(index)) %>% mutate(year = 2019)
schools.indexDowload the schoool result
In section we only need to prepare the dataset in a proper format. This index is then used to download the results for each school. The code below will download results for each school results in 2019. Because there are 5000 school results, its tedious to do manually, instead I use the power programming to iterate the process. It use for loop to iterate. The loop create a tag which correspond the HTML url for each school. Once the the tag is created, is fed into the htmltab function, which download the HTML table as data frame. Then the name, index and year columns are added for each school. In summary, the iteration prepare a tag file for each school and download and reorganize the data in tabular form for each school. Once the result for a school is download and organized is stored in the list file that is created as container .
necta2019 = list() ## preoccupied file to store list file for each shool results
for (i in 1:nrow(schools.index)){
## create a tag for each school
tag = paste0("https://maktaba.tetea.org/exam-results/CSEE2019/",schools.index$index[i],".htm")
## read a tag and mutate variable for each school
necta2019[[i]] = htmltab::htmltab(doc = tag, which = 3) %>%
mutate(index = schools.index$index[i],
school = schools.index$name[i],
year = schools.index$year[i]) %>%
as_tibble()
}Create table from a list
The function bind_rows was used to stitch together all table in the list necta2019 into a large single tibble file. Once the tibble is created, a clean_names function from janitor packages takes messy column names that have periods, capitalized letters, spaces, etc. into meaningful column names.
necta2019 = necta2019 %>%
bind_rows() %>%
janitor::clean_names() %>%
rename(school = schoo1)
necta2019 %>%
glimpse()Tidy the data
When we glimpse, we see that the dataset now has results of 482545 individuals and 8 variables including:
- cno: center of candidate
- sex: gender of candidate
- aggt: aggregated marks
- div: the division a candidate scored in the exm
- detailed_subjects: the grade for each subjects a candidate scored in the results
- index: school index
- school: name of the school
- year: the year of the exam
The internal structure of the dataset shows that the aggregate are character format, while they are suppose to be integer. The subject is a categorical variable—a descriptive type of variable with multiple levels for which the levels signify grade level (table ??). unfortunately, the way this data is organized make analysis impossible, unless structured and untidy to the right format that analytical tools can understand.
The messy state of this file mirrors the challenge of data obtained from other sources. The dataset contains more than one variables we don’t need, and uses column names that have spaces between words. The subject grades are poled in one column. All these things make the data tough to work with.
Since the candidate are grouped either private or school candiate, we need to separate the cno column into the two groups. This will allow later to analyse separate the private and from school candidate. We separate the column with the separate function from tidyr package and then select only the variable of interest wit select function from dplyr package.
necta.tb = necta2019 %>%
separate(col = cno, into = c("center", "index"), sep = "/", remove = FALSE) %>%
separate(col = center, into = c("center_type", "a"), sep = 1) %>%
select(school, center_type, sex, aggt, div, subjects = detailed_subjects)
necta.tbWe also notice that a aggt variable for some candidate is filled with -. Looking at this variable, I noticed that these are missing values and are supposed to denoted as NA instead of -. Therefore, we need to convert these values into NA. dplyr has a function called na_if which does the work as shown in the chunk below. We only need to specify the symbol that we want to change to NA.
necta.tb = necta.tb %>%
na_if("-")
necta.tbUnpack the subjects
The messy in this dataset is the subject column. Because the column combine the subjects and grades, separated with a hyphen (Table ??). We need to unpack this column so that each subjects bear its column and the corresponding values—grade for each candidate are treated as observations. This is where the stringr package comes into play (Wickham 2019).
Create location index of each subject
To separate grade and subjects, we need first to identify the locations of subjects and grade for each individual. I noticed that the location of subject for each individuals differs based on whether the candidate is private or school. The other thing make this separation hard is the present of whitespace in the subject variable. After exploring the dataset with str_locate function from stringr, I realized for each subjects there area bout four whitespace, and the number of each subjects differs depend on the whether the abbreviation used three letters (i.e CIV) or four letters(ie. ENGL). Therefore, I created a vector that contains the common subjects and assign it a name as subjects.common. I also created a vector that represent the number of character of that particular subjects and assign it a names subjects.letters. Lastly I added the number of spaces into the subjects.letters. With this small technique, I was able to detect the position of grade of each subject. Because of the number of subjects selected were 9 and the number of individuals are 482545 making a of 4.342905^{6} observations. That’s is a lot if I have to do it by clicking the mouse for each individual.
To overcome this challenge, I use the power of programming to tell a computer what to do for us with a loop. Before looping, a pre–container file was created that will store the subject location
subjects = necta.tb %>%
# slice(1:10) %>%
pull(subjects)
## create a vector of the common subjects you need to extract
subjects.common = c("CIV", "HIST", "GEO", "KISW", "ENGL", "PHY", "CHEM", "BIO", "B/MATH")
## count and create a vector of number of character for each subject
subjects.letters = c(3,4,3,4,4,3,4,3,6)
## we notice that each subject has four white space, so we add them in subjects.letters
somo.letters = subjects.letters+4
grade.location = list()
for (j in 1:length(subjects.common)){
grade.location[[j]] = subjects %>%
str_locate(pattern = subjects.common[j]) %>%
as_tibble() %>%
mutate(start = start+somo.letters[j], end = start,
subject = subjects.common[j])
}
grade.location = grade.location %>% bind_rows()grade.location %>%
drop_na() %>%
group_by(subject) %>%
slice(1,n())Create New Subjects Variables
Once we have established the locations for grades for each individual, we can use them to extract the grades and assign them to the respective subject column. Because of big number of observations to process, we iterate the process again with a for loop. But rather than using the pre–occupied contain, this time we simply extract the grades for particular subjects and bind them as column to the main dataset. The code below contains lines that was used to extract nine subjects of 482545 candindate who sat for NAtional Exams in 2019.
necta.tb = necta.tb %>% select(1:6)
for (i in 1:length(subjects.common)){
## choose the subject to extract grades
somo = grade.location %>% filter(subject == subjects.common[i])
## what is the name of the subject, we use it to rename the tibble later
kijisomo = subjects.common[i]
## extract the grades and put in the tibble
mh = str_sub(string = subjects, start = somo$start, end = somo$end) %>% as_tibble()
## change colonames
colnames(mh) = kijisomo
## stitch the subject into the dataset as a new column
necta.tb = necta.tb %>% bind_cols(mh)
}Table ?? shows the grades each individual scored for each subjects separated into columns. Candidates who never sat for a particular subject are assigned with NA for missing value. This dataset is in the right format now and can help us answer several questions.
Conclusion
In this post we have seen how to obtain HTML table archives exam results using htmltab package (Rubba 2016) and process in R using tidyverse (Wickham and Wickham 2017) and janitor packages [Firke (2020)}. The main point that I emphasize is that we must focus on how to separate grades from subjects. This is useful because it open the doors for advanced analysis in the education system in Tanzania and we might grasp some insights that are bundled in this important variable. So check the power of tools in stringr packages (Wickham 2019) that helped us to overcome the hurdle os bundled grades in subject variables. Until next time, wish you all the best in your data for education with a bonus code below that used to generate figure 1 that show the number of candidate who major either in science or arts subjects for 2019 and statistics rich figure 2 proves whether the proportion of male and female candidate in each group is significant.
necta.tb %>%
filter(center_type == "S" & sex %in% c("F", "M") & div %in% c("I", "II", "III", "IV", "0")) %>%
mutate(major = if_else(is.na(PHY), "ART", "SCIENCE")) %>%
# group_by(sex, major) %>%
# summarise(count = n())%>%
# ungroup()%>%
# mutate(percentage = count/sum(count) *100) %>%
ggplot()+
geom_bar(aes(x = sex, fill = major), position = position_dodge(.9))+
ggsci::scale_fill_jama(name = "Major\nsubject")+
facet_wrap(~div, nrow = 1)+
# coord_cartesian(expand = c(1000,0))+
ggpubr::theme_pubclean()+
theme(legend.position = "right", legend.key.height = unit(1,"lines"),
legend.key.width = unit(1,"lines"), strip.background = element_blank(), panel.background = element_rect(colour = 1, fill = NA, size = .2))+
labs(y = "candindates")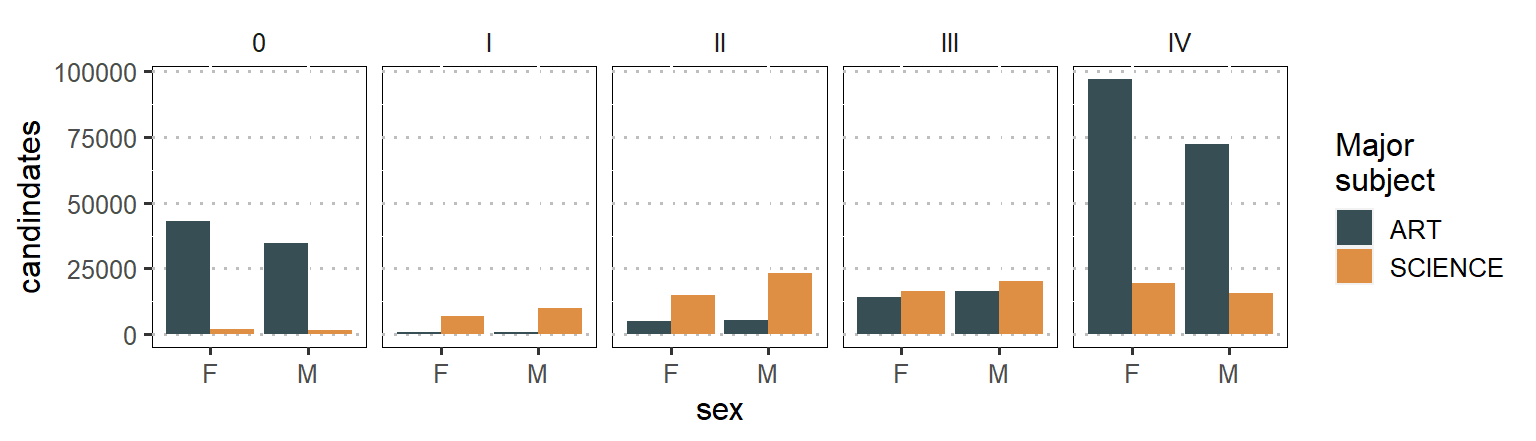
Figure 1: Number of candidate major either in sciene and arts subjects based on gender
necta.tb %>%
filter(center_type == "S" &
sex %in% c("F", "M") &
div %in% c("I", "II", "III", "IV", "0")) %>%
mutate(major = if_else(is.na(PHY), "ART", "SCIENCE")) %>%
ggstatsplot::grouped_ggbarstats(x = major, y = sex, grouping.var = div,
type = "n")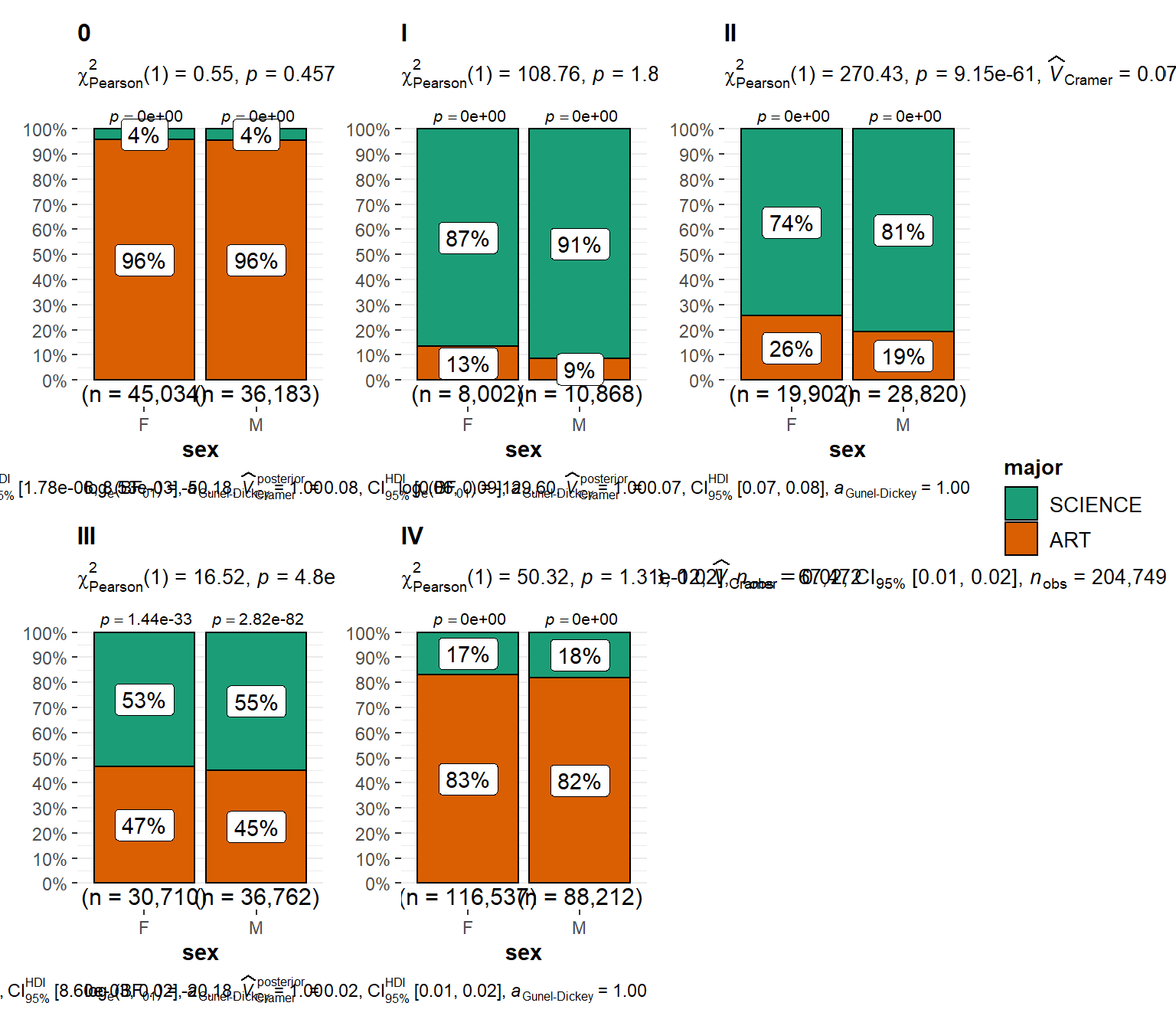
Figure 2: Number of candidate major either in sciene and arts subjects based on gender
